Tracer des isochrones avec des données et des logiciels libres🔗
Introduction
Ça fait bien longtemps que je n'ai pas discuté de SIG sur ce blog. Il faut dire que j'en fais un peu tous les jours, dans le cadre de mon activité professionnelle. Mais de temps en temps, c'est bien de se remettre dans un cadre plus libre.
Cet article a pour objectif de présenter une méthode pour tracer des isochrones: des courbes qui indiquent à quelle distance on peut aller dans une enveloppe de temps à partir d'un ou plusieurs points de départ différents.
Nous allons utiliser des outils libres mais également des données libres, avec toutes leurs contraintes. Notre objectif est de voir, en partant des gares d'un département, quelles sont les zones où l'on peut se rendre en voiture pendant un laps de temps donné. Nous allons retenir les plages de 5 minutes/10 minutes/18 minutes et 20 minutes.
Cet article n'a pas pour but d'être une référence de ce genre de calcul. Il présente juste une méthode parmi d'autres. Elle peut d'ailleurs se révéler très approximative et non adaptée à certains besoins. Voilà vous êtes prévenus…
Capture de données géographiques
Que nous faut-il ?
Avant de procéder, il faut disposer de données géographiques. C'est la base. Voici une petite liste de ce dont nous avons besoin:
- Le tracé des routes, c'est la base. C'est ce qui va constituer notre réseau de déplacement.
- Les limites de communes et de département pour pouvoir se situer plus facilement.
- Les zones résidentielles pour compléter les indications de vitesse des routes.
- Les gares et arrêts SNCF, ce seront nos points de départ ou d'arrivée. C'est ce qui va constituer les noeuds d'intérêt de notre réseau de déplacement.
Pour nos besoins, nous allons utiliser la base de données OpenStreetMap. Cette dernière est libre de droits et elle est assez complète même si, comme nous le verrons, elle pourrait être améliorée fortement.
Les données via l'API overpass
L'intérêt d'OpenStreetMap, c'est qu'on peut effectuer des requêtes via une API. Le langage est assez complexe, mais on peut vraiment récupérer ce qu'on veut.
Un moyen simple d'effectuer des requêtes est d'utiliser le requêteur overpass-turbo. Il permet de faire des requêtes à partir d'un navigateur web et, surtout, de visualiser les résultats avant de pouvoir les télécharger.
Voici un exemple commenté de requête pour récupérer des routes:
// On veut une sortie au format JSON // Au bout de 155 secondes, on arrête la requête. [out:json][timeout:155]; // On indique que la zone de recherche est identifié par le polygone // dont le nom est "Le Loroux-Bottereau", une commune du département // de Loire-Atlantique. {{geocodeArea:"Le Loroux-Bottereau"}}->.searchArea; ( // On indique qu'on veut récupérer les routes way["highway"](area.searchArea); ); // Les options pour la sortie. out body; >; out skel qt;
Avec cette requête, on peut récupérer les routes d'une commune. Néanmoins, pour notre exemple, il nous faut télécharger les routes de toutes les communes d'un département. Le faire à la main est forcément fastidieux.
Certains penseront à modifier le nom de recherche en y plaçant celui du département. Néanmoins, ils atteindront les limites de l'API. En effet, les serveurs qui fournissent le service de l'API sont partagés et ne peuvent passer trop de temps à effectuer une requête.
Dépasser les limites de l'API
Pour récupérer l'ensemble de nos routes, nous avons deux solutions:
- Télécharger une archive toute faite.
- Scripter la récupération des communes par un script shell.
Et si on faisait quand même un petit script ?
Même si c'est la méthode la moins rapide, ça vaut toujours le coup de disposer d'une méthode alternative, par exemple pour le cas où vos données ne sont pas disponibles dans le téléchargement en masse.
Concrètement, l'avantage de l'API overpass, c'est que c'est une API HTTP. On peut donc l'utiliser avec un simple client HTTP en ligne de commande comme wget ou curl (ce dernier a ma préférence).
Dans notre cas, nous avons deux choses à régler:
- Déterminer le code de la zone de recherche: sur le siteoverpass-turbo, on peut utiliser un nom comme zone de recherche mais,en vérité, une première requête est lancée sur nominatim pourtransformer ce nom en identifiant de zone.
- Lancer une boucle de requêtes qui sont suffisamment lentes pour ne pas effrayer les serveurs de l'API.
Voici un exemple de script shell commenté qui répond à ces problèmes:
#!/bin/bash echo "Récupération des routes des communes…" # Notre fichier d'entrée est un fichier csv qui contient deux # colonnes: le code osm_id et le nom de la commune. # Vous pouvez créer ce fichier en téléchargeant les communes du # département via l'API overpass et en utilisant QGIS pour fabriquer le CSV. INPUT=communes.csv OLDIFS=$IFS IFS=, [ ! -f $INPUT ] && { echo "$INPUT file not found"; exit 99; } # Le début de notre boucle while read comid comname do # On complémente à 8 chiffres l'identifiant OSM comid=$(printf "%08d" $comid) echo "Dowloading roads for $comname… ($comid)" # On précise notre requête OverPass request="[out:xml][timeout:155];area(36"${comid}')->.searchArea;(way["highway"](area.searchArea););(._;>;);out body;' # et on la joue curl 'https://overpass-api.de/api/interpreter' \ -H 'Content-Type: application/x-www-form-urlencoded; charset=UTF-8' \ -H 'Origin:https://overpass-turbo.eu' --data "$request" -o "roads_${comname}.osm" # Une méthode bourrine pour gérer les limite de l'API: on attend 10 secondes entre chaque requête. sleep 10 done < $INPUT IFS=$OLDIFS # Un script shell se termine toujours par une valeur de retour ! exit 0
Limites de département
Voici la requête overpass qui permet de récupérer la limite du département:
[out:xml][timeout:155]; {{geocodeArea:"Loire-Atlantique"}}->.searchArea; ( rel["admin_level"="6"](area.searchArea); ); (._;>;);out body;
Limites des communes
Voici la requête overpass qui permet de récupérer les limites de communes:
[out:xml][timeout:155]; {{geocodeArea:"Loire-Atlantique"}}->.searchArea; ( rel["admin_level"="8"](area.searchArea); ); (._;>;);out body;
Pour l'extraction depuis OSM, utiliser grabCommunes qui utilise l'API Overpass.
Les gares
Voici la requête overpass qui permet de récupérer les gares et arrêts de train du département:
[out:json][timeout:155]; {{geocodeArea:"Loire-Atlantique"}}->.searchArea; ( node["railway"="station"](area.searchArea); node["railway"="stop"](area.searchArea); ); (._;>;);out body;
Les zones résidentielles
Voici la requête overpass qui permet de récupérer les zones résidentielles:
[out:json][timeout:155]; {{geocodeArea:"Loire-Atlantique"}}->.searchArea; ( way["landuse"="residential"](area.searchArea); ); (._;>;);out body;
Traitement des données
Chargement
Avant de pouvoir réaliser des traitements et des analyses sur les données que nous venons de récupérer, il faut pouvoir les stocker dans un endroit adapté. En effet, nous disposons de fichiers XML qui sont certes utilisables directement dans des logiciels comme QGIS, mais qui se révèlent peu performants (pour cause d'absence d'index spatial par exemple).
De plus, nous allons devoir réaliser des traitements spécifiques qui ne sont pas accessibles à tous les formats de stockage. Pour pouvoir aller plus vite, autant prendre ce qui est le plus performant, le plus complet: PostGIS.
Je vous laisse le soin de monter un serveur PostgreSQL avec l'extension PostGIS sur votre bécane. Pour ma part, je travaille avec un serveur qui écoute sur localhost, la base de données se nomme geobase, l'utilisateur se nomme geoadmin et il n'a pas besoin de mot de passe pour se connecter (c'est mal mais rapide).
Pour le chargement des XML, j'utilise ogr2ogr sur cette forme:
ogr2ogr -overwrite -f "PostgreSQL" "PG:host=localhost dbname=geobase \ user=geoadmin" -t_srs EPSG:2154 -lco "OVERWRITE=YES" -lco "SPATIAL_INDEX=YES" \ -lco "GEOMETRY_NAME=geom" -nlt MULTILINESTRING -nln communes -progress \ initCommunes.osm lines
Cette commande permet de créer une couche PostGIS nommée communes dans la base indiquée, dans la projection Lambert93 (2154), avec des index spatiaux, où le champ de géométrie se nomme geom.
Si vous avez plusieurs fichiers à charger, je vous conseille d'utiliser la technique suivante:
- Renommer un des fichiers que vous avez à importer en initCommunes.osm
- Utilisez le script suivant:
#!/bin/bash # Import initial, permet de créer la structure ogr2ogr -overwrite -f "PostgreSQL" "PG:host=localhost dbname=geobase \ user=geoadmin" -t_srs EPSG:2154 -lco "OVERWRITE=YES" -lco "SPATIAL_INDEX=YES" \ -lco "GEOMETRY_NAME=geom" -nlt MULTIPOLYGONS -nln communes -progress \ initCommunes.osm multipolygons # Boucle d'ajout ! find ./ -name 'communes_*.osm' | while read com do echo "$com" ogr2ogr -append -f "PostgreSQL" "PG:host=localhost dbname=geobase user=geoadmin" \ -t_srs EPSG:2154 -nlt MULTIPOLYGONS -nln communes -progress "$com" \ multipolygons done exit 0
Attention, pour les données des gares, je vous conseille de supprimer les données en double: certaines gares ont également des points d'arrêt.
Amélioration des données de routes: phase 1
Les données brutes sont chargées, mais il reste néanmoins à les retravailler:
- D'abord, il y a des chances que les données de routes soient en doublons dans certains cas.
- Ensuite, il faut faire un peu de ménage dans les champs de cette couche.
- Il faut croiser cette donnée avec les zones résidentielles.
- Enfin, il faut s'assurer de disposer d'un réseau topologique correct.
Pour ces opérations de corrections, nous allons utiliser PostGIS et GRASS.
Dans un premier temps, il faut faire un peu de ménage, dans PostGIS:
-- Nettoyage des données de routes ---- Suppression des doublons géographiques DELETE FROM routes WHERE ogc_fid IN (select ogc_fid from ( SELECT ogc_fid, ROW_NUMBER() OVER(PARTITION BY geom ORDER BY ogc_fid asc) AS Row, geom FROM ONLY public.routes ) dups where dups.Row > 1 order by ogc_fid); ---- Un peu de ménage, on supprime les routes non utiles dans notre étude DELETE FROM routes WHERE highway IN ('track', 'bus_stop', 'bus_guideway', 'construction', 'crossing', 'cycleway', 'disused', 'footway', 'proposed', 'raceway', 'rest_area', 'service', 'access', 'bridleway', 'path', 'pedestrian', 'platform','steps', 'road'); ---- Modification du champ nom s'il est vide UPDATE routes SET name = substring(other_tags from '"ref"=>"([^\"]+)".*$') WHERE name IS NULL AND other_tags ~ '.*"ref"=>".*'; ---- Un peu de ménage dans les champs ALTER TABLE routes DROP COLUMN IF EXISTS waterway;; ALTER TABLE routes DROP COLUMN IF EXISTS aerialway; ALTER TABLE routes DROP COLUMN IF EXISTS z_order; ALTER TABLE routes DROP COLUMN IF EXISTS barrier; ALTER TABLE routes DROP COLUMN IF EXISTS man_made; ALTER TABLE routes ADD COLUMN maxspeed NUMERIC(10,2); ---- Pré-affectation des vitesses en fonction du type de route ---- Récupération de la donnée OSM UPDATE routes SET maxspeed = substring(other_tags from '"maxspeed"=>"([^\"]+)".*$')::NUMERIC(10,2) WHERE other_tags ~ '.*"maxspeed"=>".*' AND substring(other_tags from '"maxspeed"=>"([^\"]+)".*$') ~ '^\d+$'; ---- Les cas spéciaux sont à 50 km/h UPDATE routes SET maxspeed = 50.0 WHERE other_tags ~ '.*"maxspeed"=>".*' AND maxspeed IS NULL; UPDATE routes SET maxspeed = 130.0 WHERE highway IN ('motorway') AND maxspeed IS NULL; UPDATE routes SET maxspeed = 90.0 WHERE highway IN ('motorway_link', 'trunk_link') AND maxspeed IS NULL; UPDATE routes SET maxspeed = 50.0 WHERE highway IN ('residential') AND maxspeed IS NULL; -- Croisement avec les zones résidentielles ---- Aggrégation des zones résidentielles DROP TABLE IF EXISTS agg_resi; CREATE TABLE agg_resi AS SELECT 1 as gid, ST_Union(p.geom) as geom from residentials p; CREATE INDEX agg_resi_geomidx ON public.agg_resi USING gist (geom); -- On créé une colonne pour indiquer qu'on veut supprimer des lignes ALTER TABLE routes DROP COLUMN IF EXISTS todelete; ALTER TABLE routes ADD COLUMN todelete BOOLEAN DEFAULT False; -- On remplit cette colonne avec l'information UPDATE routes a SET todelete = True FROM residentials p WHERE ST_Intersects(a.geom, p.geom) AND a.highway IN ('primary','secondary','tertiary', 'unclassified'); -- On ajoute les routes découpées --- Attention, cette requête prend beaucoup de temps… INSERT INTO routes (osm_id, name, highway, other_tags, maxspeed, todelete, geom) SELECT a.osm_id, a.name, a.highway, a.other_tags, a.maxspeed, a.todelete, ST_Multi(a.clipped_geom) FROM ( SELECT l.osm_id, l.name, l.highway, l.other_tags, 50::integer AS maxspeed, False As todelete, (ST_Dump(ST_Intersection(p.geom, l.geom))).geom As clipped_geom FROM routes l INNER JOIN agg_resi p ON ST_Intersects(l.geom, p.geom) WHERE l.highway IN ('primary','secondary','tertiary', 'unclassified') UNION SELECT l.osm_id, l.name, l.highway, l.other_tags, 80::integer AS maxspeed, False As todelete, (ST_Dump(ST_Difference(l.geom, p.geom))).geom As clipped_geom FROM routes l INNER JOIN agg_resi p ON ST_Intersects(l.geom, p.geom) WHERE l.highway IN ('primary','secondary','tertiary', 'unclassified') ) a WHERE ST_Dimension(a.clipped_geom) = 1; -- On retire les routes à supprimer DELETE FROM routes WHERE todelete = True; -- On supprime la colonne todelete ALTER TABLE routes DROP COLUMN todelete; -- On vire la table d'aggrégation DROP TABLE IF EXISTS agg_resi;
Amélioration des données de routes: phase 2
Ensuite, il nous faut créer un vrai réseau topologique. En effet, ce qui sort d'OSM est un ensemble de routes qui ne se coupent pas forcément au niveau des intersections. Globalement, ça peut poser des problèmes pour les traitements futurs de GRASS.
Pour y pallier, il va nous falloir faire un peu de ménage avec GRASS. Vous devez donc disposer d'une DB GRASS et avoir GRASS7 lancé. Nous allons juste lancer un script de nettoyage qui a la forme suivante:
#!/bin/bash # Nettoyage du réseau routier dans GRASS ## On effectue un lien vers les données PostGIS echo "Import des données de route depuis PostGIS…" g.remove -f type=vector name=routes g.remove -f type=vector name=c_routes v.in.ogr --overwrite -o input="PG:dbname=geobase user=geoadmin host=localhost" layer=routes output=routes type=line # Nettoyage des routes (on recalcule la topologie et on vire les doublons) v.clean --overwrite -c input=routes output=c_routes type=line tool=break,rmline,rmdupl # On exporte en GPKG car GRASS a un problème pour écrire directement # dans la base PostgreSQL v.out.ogr --overwrite input=c_routes output="data.gpkg" format=GPKG layer=1 type=line output_layer=c_routes # puis on utilise ogr2ogr pour faire le transfert ogr2ogr -overwrite -f "PostgreSQL" "PG:host=localhost dbname=geobase \ user=geoadmin" -t_srs EPSG:2154 -lco "OVERWRITE=YES" -lco "SPATIAL_INDEX=YES" \ -lco "GEOMETRY_NAME=geom" -nlt MULTILINESTRING -nln croutes -progress data.gpkg \ c_routes exit 0
En sortie, on dispose de la couche croutes dans PostGIS. Il nous reste à calculer les coûts de déplacement.
Amélioration des données de routes: phase 3
Maintenant qu'on dispose d'un réseau topologique correct, il reste une dernière étape de calcul des coûts de déplacement. Comme nous souhaitons réaliser des isochrones, le coût va être exprimé dans une unité de temps (secondes dans notre cas).
J'ai pris l'hypothèse fortement discutable de prendre un temps de trajet par tronçon égal au temps de parcours à la vitesse maximale du tronçon.
Néanmoins, pour pondérer un peu les résultats, j'ai délibérément abaissé les vitesses en suivant les règles suivantes:
- Vitesse limitée à 90 km/h ⇒ 80 km/h
- Vitesse limitée à 80 km/h ⇒ 70 km/h
- Vitesse limitée à 50 km/h ⇒ 40 km/h
- Vitesse limitée à 30 km/h ⇒ 25 km/h
Mettons tout ça en musique via PostGIS:
-- Calcul des coûts de déplacement -- On va dire que toutes les routes qui n'ont pas de maxspeed sont à 50 km/h pour les non classées UPDATE croutes SET maxspeed = 50.0 WHERE maxspeed IS NULL AND highway IN ('unclassified', 'living_street'); -- On va dire que toutes les routes qui n'ont pas de maxspeed sont à 80 km/h pour les non classées UPDATE croutes SET maxspeed = 80.0 WHERE maxspeed IS NULL AND highway NOT IN ('unclassified', 'living_street'); -- On abaisse les vitesses suivant les règles sus-citées UPDATE croutes SET maxspeed = 80.0 WHERE maxspeed = 90.0; UPDATE croutes SET maxspeed = 70.0 WHERE maxspeed = 80.0; UPDATE croutes SET maxspeed = 50.0 WHERE maxspeed = 50.0; UPDATE croutes SET maxspeed = 25.0 WHERE maxspeed = 30.0; -- Enfin, on calcule les coûts de déplacement. ALTER TABLE croutes DROP COLUMN IF EXISTS cost; ALTER TABLE croutes ADD COLUMN cost NUMERIC(10,2); UPDATE croutes set cost = (ST_Length(geom)/(maxspeed/3.60)) where maxspeed > 0;
Ok, nous avons de quoi calculer des isochrones.
Calcul des isochrones
Ce calcul va se faire dans GRASS, non pas parce que c'est l'optimum, mais juste parce que c'est la seule méthode que je connaisse, en plus de PgRouting.
Pour le calcul des isochrones, nous allons utiliser nos données de routes qui vont constituer le réseau et nos données de gares qui vont constituer des centres de départ sur ce réseau.
GRASS dispose de fonctions dédiées au réseau (les fonctions v.net), que nous allons utiliser.
Le script suivant contient ce qu'il faut pour réaliser le calcul d'isochrones. Il doit être lancé dans l'environnement shell de GRASS:
#!/bin/bash # Calcul d'isochrones dans GRASS # On relie les données utiles dans la base GRASS sans faire d'import. # C'est inutile dans notre cas car les fonctions de réseau vont dupliquer les données à leur sauce. echo "Import des données depuis PostGIS…" v.external -o --quiet --overwrite input="PG:host=localhost user=geoadmin dbname=geobase" layer=gares output=gares v.external -o --quiet --overwrite input="PG:host=localhost user=geoadmin dbname=geobase" layer=croutes output=croutes # Nettoyage des routes # v.clean --overwrite -c input=routes output=c_routes type=line tool=break,rmline,rmdupl # Construction du réseau ## Ici, on va construire un réseau au sens GRASS du terme. On part de notre ## couche de routes, on la convertie en réseau et on y adjoint les centres (les ## gares). Elles sont ajoutées au réseau par un trait de base. echo "Construction du réseau…" v.net --quiet -s --overwrite input=croutes points=gares output=thenetwork \ operation=connect arc_type=line threshold=50 # lier les bases de données des routes et des noeuds (uniquement si v.in.ogr): #v.db.connect -o map=thenetwork@PERMANENT table=gares layer=2 # v.db.connect -o map=network@PERMANENT table=routes layer=1 # Calcul des isochrones echo "Calcul des isochrones…" ## Ici, on prend toutes les gares et on calcule les isochrones sur des limites ## de coûts de 300, puis de 600 puis de 1080 puis de 1200. ## Cette opération casse le réseau selon les limites. Comme notre coût est un ## temps, 300 correspond donc à 5 minutes (300 secondes). v.net.iso -u --overwrite input=thenetwork@PERMANENT output=isochrones@PERMANENT \ center_cats=1-1000 costs=300,600,1080,1200 arc_column=cost # Nettoyage des valeurs à -1 dans les isochrones echo "Suppression des valeurs inutiles…" v.edit --quiet map=isochrones tool=delete layer=1 type=line where="center=-1 or isonr>=5" # Exporter les données dans PostGIS (rapide) mais doit être défini dans db.connect. echo "Export des données…" v.out.ogr --overwrite -c input=isochrones output="PG:dbname=geobase" \ format=PostgreSQL layer=1 type=line \ lco="OVERWRITE=YES,SCHEMA=public,GEOMETRY_NAME=geom,FID=fid" \ output_layer=isochrones exit 0
Créer les polygones des zones
Vous devriez pouvoir afficher les poly-lignes des isochrones. Concrètement, chaque coût cumulé a été injecté dans chaque tronçon de route suivant les 4 classes énoncées plus haut (300,600,1080,1200).
Il reste à générer des polygones à partir de ces éléments. Pour ça, le plus simple consiste à utiliser PostGIS avec les requêtes qui suivent:
-- Calcul des zones d'isochrones ---- On commence par créer la tables des zones iso DROP TABLE IF EXISTS isozones; CREATE TABLE public.isozones ( fid serial, center integer, classe integer, geom geometry(MultiPolygon, 2154), CONSTRAINT isonzones_pk PRIMARY KEY (fid) ) WITH ( OIDS=FALSE ); ALTER TABLE public.isozones OWNER TO geoadmin; CREATE INDEX isozones_geom_idx ON public.isozones USING gist (geom); -- Remplissage de la table des zones INSERT INTO isozones (center, classe, geom) SELECT center, isonr, ST_Multi(ST_ConvexHull(ST_Collect(geom))) as geom FROM isochrones GROUP BY center, isonr; -- Zones fusionnées ---- Ensuite, on va aggréger les zones par classe DROP TABLE IF EXISTS merged_isozones; CREATE TABLE public.merged_isozones ( fid serial, classe integer, geom geometry(MultiPolygon, 2154), CONSTRAINT merged_isozones_pk PRIMARY KEY (fid) ) WITH ( OIDS=FALSE ); ALTER TABLE public.merged_isozones OWNER TO geoadmin; CREATE INDEX merged_isozones_geom_idx ON public.merged_isozones USING gist (geom); -- Remplissage de la table des zones TRUNCATE TABLE merged_isozones; INSERT INTO merged_isozones (classe, geom) SELECT classe, ST_Multi(ST_Union(geom)) as geom FROM isozones GROUP BY classe; -- Découpage manuel des classes ---- Je sais, c'est crade mais c'est rapide. UPDATE merged_isozones SET geom = ST_Multi(ST_Difference(b.geom, a.geom)) FROM (SELECT geom FROM merged_isozones WHERE classe = 1) a, (SELECT geom FROM merged_isozones WHERE classe = 2) b WHERE classe = 2; UPDATE merged_isozones SET geom = ST_Multi(ST_Difference(b.geom, a.geom)) FROM (SELECT ST_Union(geom) as geom FROM merged_isozones WHERE classe IN (1,2)) a, (SELECT geom FROM merged_isozones WHERE classe = 3) b WHERE classe = 3; UPDATE merged_isozones SET geom = ST_Multi(ST_Difference(b.geom, a.geom)) FROM (SELECT ST_Union(geom) as geom FROM merged_isozones WHERE classe IN (1,2,3)) a, (SELECT geom FROM merged_isozones WHERE classe = 4) b WHERE classe = 4;
Affichage dans QGIS
Les données sont maintenant disponibles pour visualisation dans QGIS. En guise de fond de plan, vous pouvez utiliser les tuiles TMS d'OpenStreetMap:
https://a.tile.openstreetmap.org/{z}/{x}/{y}.png
Avec les éléments présentés précédemment, j'arrive à constituer la carte suivante:
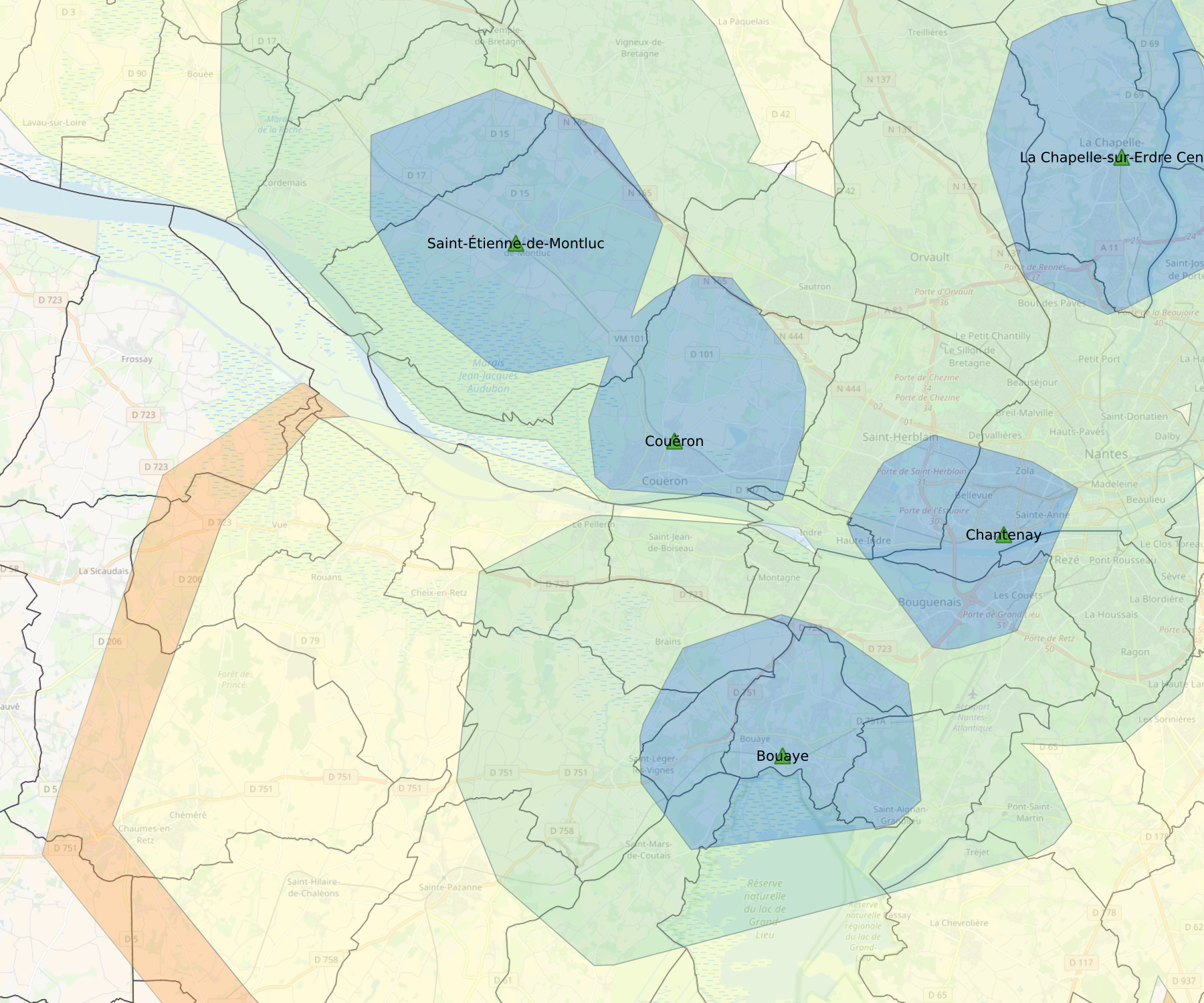
Tout ça pour ça ? Oui mais maintenant vous savez faire. À vous de l'adapter à vos besoins.
Conclusions
Bon, c'était assez compliqué et ce, pour plusieurs raisons. La première c'est que les données d'OpenStreetMap ne sont pas encore assez fines, notamment au niveau des limites de vitesse. J'ai dû batailler pour trouver quelques techniques pour les déduire d'autres couches.
Par ailleurs, les routes OpenStreetMap ne forment pas du tout un réseau topologique (enfin du moins, en sortie de l'API overpass) ce qui pose de nombreux problèmes pour GRASS. Nous arrivons à contourner ces éléments mais cela impose d'ajouter quelques requêtes.
Enfin, ça fait longtemps que je n'ai pas vraiment fait de SIG libre: je suis donc un peu rouillé et il doit y avoir des techniques pour aller plus vite, avec d'autres opérateurs.
Le choix de PostGIS peut sembler bizarre de prime abord, essentiellement parce que finalement, tous les traitements se font sur la même machine. Au départ, j'avais commencé avec le format standard GPKG qui est vraiment bien géré par QGIS et GDAL. Mais finalement, vu les traitements imposés pour le nettoyage des données, je me suis retrouvé à court de fonctions géométriques dans Spatialite (GPKG est une surcouche de Spatialite). Je me suis rabattu vers PostgreSQL/PostGIS qui a effectivement tenu ses promesses.
Au final, on obtient des isochrones avec tous les détails pour rejouer les calculs avec d'autres classes de coût de déplacement. On pourrait aussi aller plus loin en recalculant les coûts en fonction de la présence d'éléments de signalisation qui imposent ou non un arrêt.
Mais d'ici là, et en restant approximatif, on obtient des zones pas si délirantes que ça en comparant avec ce que peuvent produire OSRM ou même Google Maps dans leur calcul de distance.
Pour terminer, on aurait pu s'affranchir de GRASS si nous avions utilisé PgRouting. Mais je souhaitais aussi montrer que le SIG GRASS avait encore des atouts sur la partie des réseaux.