Faire des cartes d'analyse avec QGIS 1.3.0 et PostGIS 1.3🔗
Introduction
Dans le monde des SIG libres, le choix des outils d'analyse est assez limité:
- GRASS pour les manipulations complexes (car la prise en main de GRASS est assez complexe, il faut le reconnaître).
- QGIS pour l'affichage simple.
- PostgreSQL/PostGIS permet également de faire des traitements mais pas de les afficher simplement.
D'où la question: existe-t-il un moyen simple et efficace de représenter de l'information géographique travaillée et non brute de décoffrage ? Ma tentative de réponse vient à la suite de cet article… Pour faire simple, disons, que oui c'est possible avec un peu d'entraînement et surtout une bonne base de travail.
Le contexte de ce travail est d'utiliser uniquement QGIS et PostGIS pour afficher des cartes d'analyses. Une carte d'analyse est une carte qui croise de l'information géographique avec des données alphanumériques. Elles sont très utilisées en statistiques par exemple et en termes d'efficacité, avec un outil comme MapInfo Pro (utilisation des analyses thématiques) et des données correctes, ce genre de carte prend 15 minutes environ à créer.
Nous voulons effectuer des croisements d'informations simples. Par exemple, colorier une commune en fonction d'une valeur donnée. Cette valeur n'est pas située dans une table géographique mais dans une table simplement alphanumérique.
Les capacités de traitement de QGIS sont vraiment très limitées. On peut utiliser certains plugins genre ftools mais leur utilisation est assez complexe et surtout pas réservée à ce que nous voulons faire. En plus, ça ne fonctionne pas sur PostGIS. D'où l'idée d'utiliser les capacités de traitement de PostgreSQL et de PostGIS pour faire le travail. QGIS se contentera de l'affichage.
Tout est très simple…

![]()
Prérequis
Je suppose que vous avez QGIS (l'exemple fonctionne avec la version 1.3.0 sous Debian Squeeze, compilée à la main, car le paquet disponible sur gfoss.it est buggé) et un serveur PostgreSQL sous la main avec l'extension PostGIS. Si ce n'est pas le cas, Google est votre ami et il vous donnera des tonnes de sites qui expliquent comment on fait pour mettre en place l'infrastructure.
Pour simplifier le sujet serveur PostgreSQL, on va dire qu'il est situé sur localhost, que la base de données utilisée sera nommée "GEOBASE_LOCALE" et que l'utilisateur qgis a tous les droits dessus, y compris celui de créer des tables.
Je suppose aussi que vous disposez de l'outil ogr2ogr (pour le chargement des données).
Une modélisation light
Voyons maintenant ce que ça donne sur un exemple concret:
- Nous avons le dessin des départements dans une table géographique (nommée DEPARTEMENT).
- Nous avons une donnée qui nous intéresse dans la table UTILISATEUR_LINUX.
La table DEPARTEMENT est une table contenant le dessin géométrique des communes du département. Elle est composée des champs suivants:
- code_dept: Code à deux caractères du département.
- the_geom: le champ géographique du département.
La table UTILISATEUR_LINUX contient des informations alphanumériques sur les utilisateurs de GNU/Linux. Une ligne correspond non pas à une commune mais à un utilisateur.
Pour chaque ligne, on a les champs suivants:
- ID_USER: identifiant de l'utilisateur.
- DEPARTEMENT: code sur deux chiffres du département de l'utilisateur.
- NB_MACHINES: Nombre de machines sous GNU/Linux de cet utilisateur.
Le lien entre la table géographique et la table alphanumérique est le code INSEE (champ INSEE dans les deux tables).
Pour la table UTILISATEUR_LINUX, on aurait pu choisir un modèle plus simple (genre une ligne par commune) mais le modèle de cette table va nous permettre de faire quelques agrégations… Ça ne fait jamais de mal de voir ce qu'on peut faire comme calculs avec un peu de SQL.
Au final, nous allons créer une table géographique nommée LINUX qui contiendra les objets géographiques et les données alphanumériques qui nous intéressent à savoir:
- Nombre d'utilisateurs par département.
- Nombre de machines par département.
- Densité utilisateur: nombre d'utilisateurs par millier de km2 par département.
- Densité machines: nombre de machines par millier de km2 par département.
Récupérer les données
Pour les données géographiques, j'ai utilisé la couche GEOFLA des départements produite par l'IGN. Ces données sont non libres (pas d'exploitation commerciale) mais gratuites au format Shapefile (lien pour les télécharger) . Je vous conseille de télécharger dans la projection RGF93 car la suite des manipulations utilise cette projection.
Les données sont au format shapefile. Il faut donc les convertir et les charger dans le serveur PostGIS, ce que nous allons faire avec shp2pgsql comme suit:
shp2pgsql -s 2154 -d DEPARTEMENT DEPARTEMENT | psql -h localhost -U qgis -W GEOBASE_LOCALE
L'option -s 2154 permet de spécifier la projection (2154 correspond à RGF93) et -d permet d'effacer la table si elle existe déjà.
Pour les données de la table UTILISATEUR_LINUX, j'ai créé une table remplie avec des valeurs aléatoires dont vous pouvez disposer ici. Il s'agit d'un script SQL contenant des valeurs aléatoires. Pour injecter les données, il suffit de faire:
psql -h localhost -U qgis -W GEOBASE_LOCALE -f UTILISATEUR_LINUX.sql
Quelques précautions techniques
Avant de créer une table géographique, il ne faut pas oublier que QGIS impose certaines règles lors de la création de tables. D'abord, pour que QGIS liste la table LINUX, il est indispensable que les colonnes géographiques soient renseignées dans la table "geometry_columns". C'est le comportement normal de PostGIS aussi, mais pas de PostgreSQL. L'ajout de cette information dans la table peut être effectué de deux manières. La technique utilisée est l'emploi de la requête suivante:
De plus, QGIS exige que la table dispose d'un champ d'identification qui doit être de type int et disposer d'une contrainte de clef unique. Enfin, QGIS travaille avec des valeurs plutôt en réel (float8) qu'en entier (integer). Cette contrainte impose que les résultats de requête soient convertis avant de pouvoir travailler avec.
Créer une couche avec des valeurs de référence et une donnée géographique
L'objectif est de créer une couche en utilisant une jointure pour lier un objet géographique à une ou plusieurs valeurs. Ensuite, on utilisera QGIS pour affecter la couleur et gérer les classes.
Cette requête permet de créer la table géographique LINUX en croisant les données géographiques de la table DEPARTEMENT et les données alphanumériques de la table UTILISATEUR_LINUX en effectuant une agrégation d'informations (Nombre d'utilisateurs, nombre de machines, densité d'utilisateurs et densité de machines). Cette couche répond aux exigences de QGIS.
Visualiser le résultat
Le travail est centré sur les onglets de propriétés de la couche dans QGIS:
- Ouvrir QGIS.
- Se connecter au serveur PostGIS.
- Ouvrir la table LINUX.
- Normalement, une vue par défaut s'affiche tout est en couleur unie.
- Faire un clic droit sur la couche et choisir le menu "Propriétés".
- Choisir l'onglet "Convention des signes".
C'est dans cet onglet que l'on peut régler la représentation de la couche. QGIS nous propose 4 modes de représentation:
- Par symbole unique: chaque objet ponctuel se voit attribuer un symbole suivant des éléments. Dans notre cas, la couche étant surfacique, le menu ne propose rien.
- Par symbole gradué: chaque objet géographique se voit attribuer un style suivant son appartenance à une classe. C'est ce que nous voulons pour travailler ici sur les densités.
- Par couleur continue: chaque objet géographique se voit attribuer une couleur suivant une classe prédéfinie. Dans notre cas, la représentation ne donne pas grand-chose.
- Par valeur unique: chaque valeur unique de l'objet géographique se voit attribuer un style. Ça ressemble aux classes, en plus simple, si on a des valeurs discrètes.
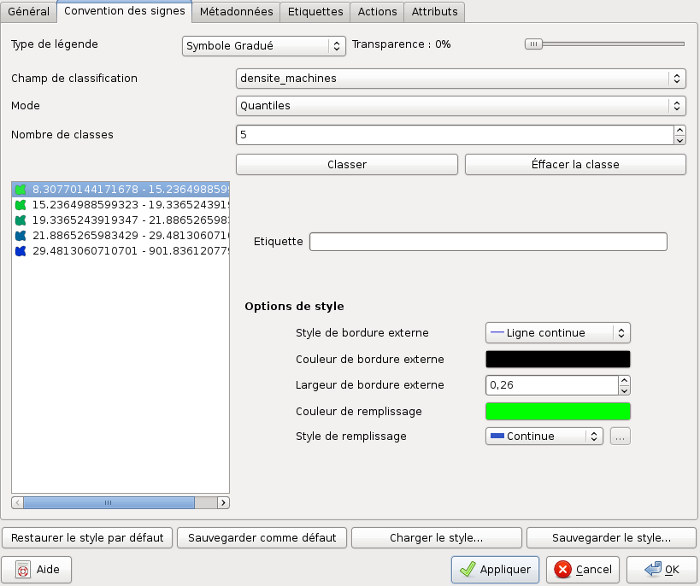
Dans notre cas, seules les densités sont représentables avec les objets surfaciques des départements. Nous allons donc utiliser le symbole gradué. La représentation qui utilise ce mode est très intéressante dans QGIS car elle permet de créer des classes de manière assez simple:
- Choisir "Symbole gradué" dans la liste déroulante intitulée "Type de Légende".
- Choisir le champ qu'on désire représenter (ici: densité_machines).
- On peut sélectionner deux modes: par intervalles réguliers, c'est-à- dire que les classes sont espacées de manière régulière entre elles (de 10 en 10 par exemple). On peut également choisir par quantiles c'est-à-dire que les classes sont construites de manière à représenter un nombre égal d'objets. Vu l'expression de notre densité de machines qui correspond au nombre de machines réparties en milliers de km2, la distribution est très inégale: les densités les plus importantes sont forcément dans les plus petits départements. Il nous faut donc, dans ce cas, choisir le mode par quantiles.
- Choisir le nombre de classes: 5 par exemple.
- Générer les classes en cliquant sur le bouton "Classer"
- Cliquer sur OK pour affecter la représentation à la carte.
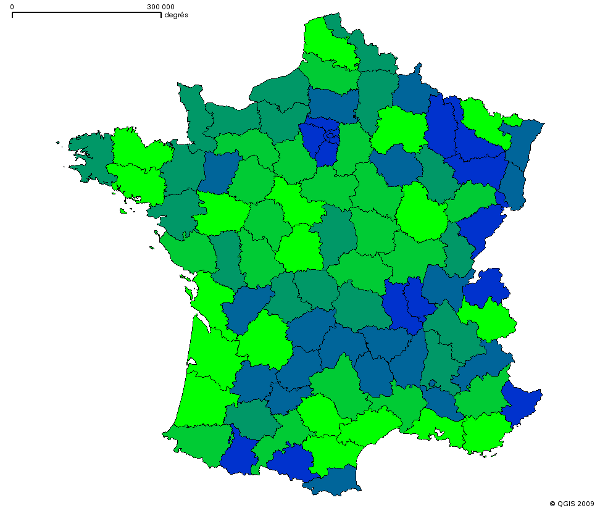
Voici ce qu'on obtient:
Créer une carte avec des points de couleur
Le principe est le même que précédemment. Toutefois, au lieu de prendre l'objet géographique, on va utiliser son centroïde pour y positionner un symbole. Nous allons donc avoir besoin de la fonction PostGIS: ST_Centroid().
Cette requête permet de créer quasiment la même table qu'auparavant mais génère des points et non des surfaces. Pour faire une carte digne de ce nom, il convient d'utiliser également les surfaces, histoire d'améliorer le support visuel. On a donc intérêt à ouvrir les couches LINUX_POINT et LINUX (ordre des calques également). La couche LINUX sert uniquement de fond de carte, on va donc l'ouvrir et choisir une couleur neutre.
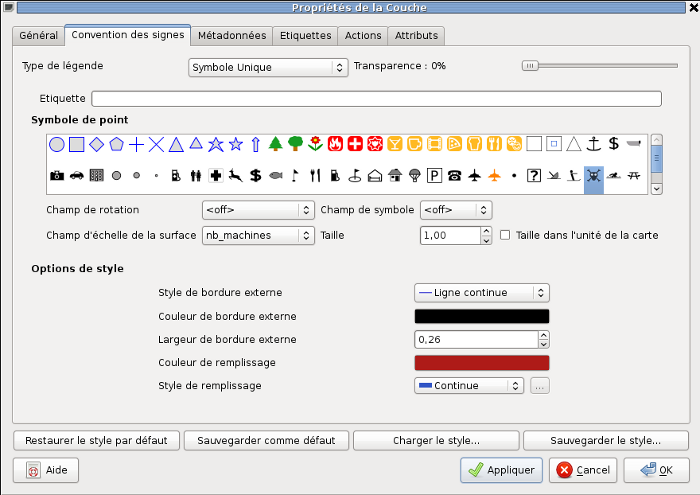
Travaillons maintenant sur la couche LINUX_POINT:
- Nous désirons afficher un symbole dont la taille sera proportionnelle au nombre de machines.
- Aller sur l'onglet convention des signes.
- Choisir le type de légende: symbole unique.
- Choisir le symbole (le crâne de hacker).
- Choisir le champ d'échelle de la surface: nb_machines.
- On peut employer le multiplicateur en bougeant les valeurs du champ "Taille".
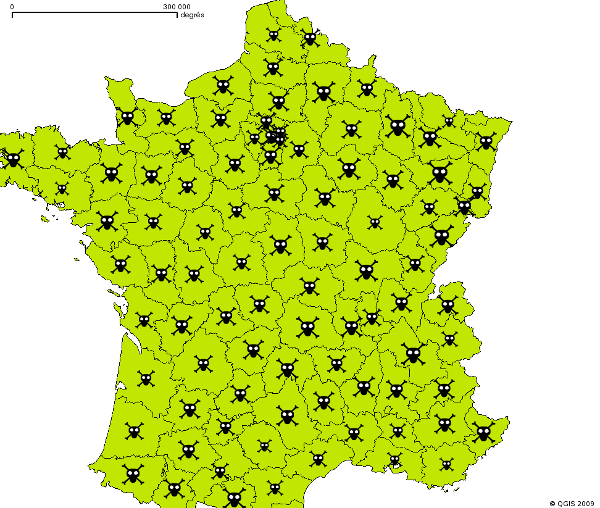
Voici le résultat final:
Utiliser des vues
Notre mode opératoire permet de publier assez rapidement des cartes. Toutefois, si les données de la table UTILISATEUR_LINUX changent, il faut supprimer les couches (par la requête SELECT dropgeometrytable('COUCHE')) et relancer les requêtes de croisement. Cela peut se révéler assez fastidieux si la table change régulièrement. Heureusement, PostgreSQL peut nous aider grâce à son concept de vue: une vue est une requête SELECT qui se lance à chaque fois qu'on interroge la vue. Donc si la requête est longue, le résultat met du temps à s'afficher.
Pour utiliser des vues, il suffit d'employer le terme CREATE VIEW au lieu de CREATE TABLE dans les requêtes de croisement d'information. L'intérêt des vues c'est que l'on ne stocke rien en dur et que les données sont toujours à jour par rapport à la table de référence. Le plus important est bien d'affecter la colonne géométrie dans la table de référence.
Si on utilise ensuite QGIS, on ne verra aucune différence: la table est présente et rien n'indique que c'est une vue. En revanche, le premier affichage est plus long: c'est à ce moment que la requête est lancée. Dans notre cas, c'est assez rapide tout de même.
Une idée: "Travailler avec des tables temporaires" ?
PostgreSQL supporte le concept de tables temporaires. Toutefois, ces dernières se suppriment automatiquement à la fin du pool de requête. Je n'ai pas trouvé comment les utiliser concrètement. Les vues me semblent mieux adaptées à notre objectif.